

What exactly is biotechnology, and how could it change our approach to human health?
As the age of big data transforms the potential of this emerging field, members of the World Economic Forum’s Global Future Council on Biotechnology tell you everything you need to know.
A brief introduction to biotech
Elizabeth Baca, Specialist Leader, Deloitte Consulting, and former Deputy Director, California Governor’s Office of Planning and Research & Elizabeth O’Day, Founder, Olaris, Inc
What if your doctor could predict your heart attack before you had it – and prevent it? Or what if we could cure a child’s cancer by exploiting the bacteria in their gut?
These types of biotechnology solutions aimed at improving human health are already being explored. As more and more data (so called “big data”) is available across disparate domains such as electronic health records, genomics, metabolomics, and even life-style information, further insights and opportunities for biotechnology will become apparent. However, to achieve the maximal potential both technical and ethical issues will need to be addressed.
As we look to the future, let’s first revisit previous examples of where combining data with scientific understanding has led to new health solutions.
Biotechnology is a rapidly changing field that continues to transform both in scope and impact. Karl Ereky first coined the term biotechnology in 1919. However, biotechnology’s roots trace back to as early as the 1600s when a Prussian physician, Georg Ernst Stahl, pioneered a new fermentation technology referred to as “zymotechnology.”
Over the next few centuries, “biotechnology” was primarily focused on improving fermentation processes to make alcohol and later food production. With the discovery of penicillin, new applications emerged for human health. In 1981, the Organization for Economic Cooperation and Development (OECD) defined biotechnology as, “the application of scientific and engineering principles to the processing of materials by biological agents to provide the goods and services.”
Today, the Biotechnology Innovation Organization (BIO) defines biotechnology as “technology based on biology – biotechnology harnesses cellular and biomolecular processes to develop technologies and products that help improve our lives and the health of our planet.
In the Fourth Industrial Revolution, biotechnology is poised for its next transformation. It is estimated that between 2010 and 2020 there will be a 50-fold growth of data.
Just a decade ago, many did not even see a need for a smart phone, whereas today, each click, step we take, meal we eat, and more is documented, logged and analyzed on a level of granularity not possible a decade ago.
Concurrent with the collection of personal data, we are also amassing a mountain of biological data (such as genomics, microbiome, proteomics, exposome, transcriptome, and metabolome). This biological-big-data coupled with advanced analytical tools has led to a deeper understanding about fundamental human biology. Further, digitization is revolutionizing health care, allowing for patient reported symptoms, feelings, health outcomes and records such as radiographs and pathology images to be captured as mineable data.
As these datasets grow and have the opportunity to be combined, what is the potential impact to biotechnology and human health? And better still, what is the impact on individual privacy?
Disclaimer: The authors above do not necessarily reflect the policies or positions of the organizations with which they are affiliated.
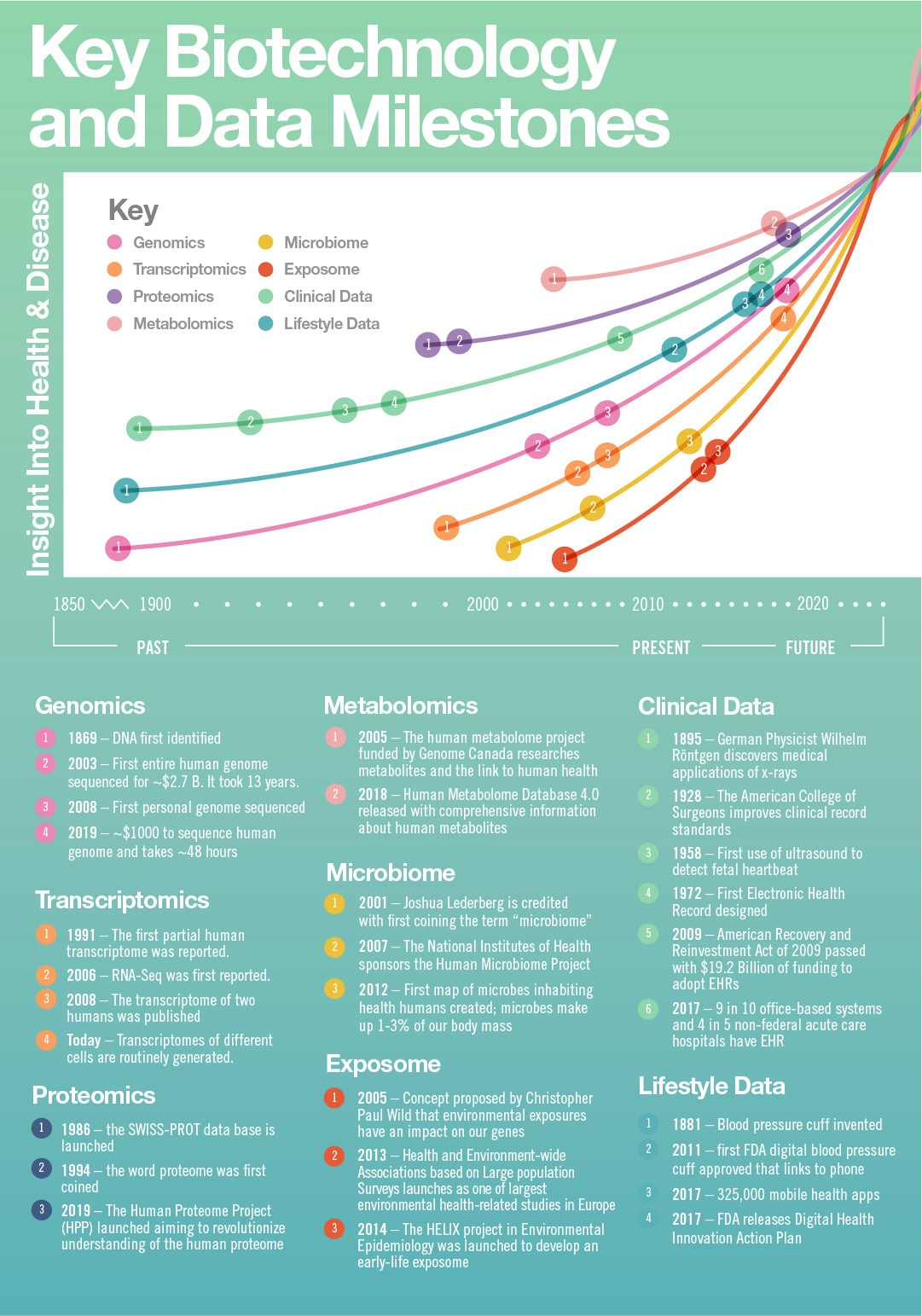
Image: Infographic developed by the California Biotechnology Foundation: A special thank you to Patricia Cooper, Executive Director, California Biotechnology Foundation
The role of big data in biotech breakthroughs
Daniel Heath, Senior Lecturer in the University of Melbourne’s Department of Biomedical Engineering & Elizabeth Baca & Elizabeth O’Day
One of the most fundamental and powerful data sets for human health is the human genome. DNA is our biological instruction set composed of billions of repeating chemical groups (thymine, adenine, guanine, and cytosine) that are connected to form a code. A person’s genome is the complete set of his or her DNA code, ie the complete instructions to make that individual.
DNA acts as a template to produce a separate molecule called RNA through the process of transcription. Many RNA molecules in turn act as a template for the production of proteins, a process referred to as translation. These proteins then go on to carry out many of the fundamental cellular tasks required for life. Therefore any unwanted changes in DNA can have downstream effects on RNA and proteins. This can have little to no effect or result in a wide range of diseases such as Huntington’s disease, cystic fibrosis, sickle cell anaemia, and many more.
Genomic sequencing involves mapping the complete set, or part of individual’s DNA code. Being able to detect unwanted changes in DNA not only provides powerful insight to understand disease but can also lead to new diagnostic and therapeutic interventions.
The first human genome sequence was finished in 2003, took 13 years to complete, and cost billions of dollars. Today due to biotech and computational advancements, sequencing a person’s genome costs approximately $1,000 and can be completed in about a day.
Important milestones in the history of genomics
1869 – DNA was first identified
1953 – Structure of DNA established
1977 – DNA Sequencing by chemical degradation
1986 – The first semi-automated DNA sequencing machine produced
2003 – Human genome project sequenced first entire genome at the cost of $3 billion
2005 – Canada launches personal genome project
2007 – 23andMe markets first direct to consumer genetic testing for ancestry of autosomal DNA
2008 – First personal genome sequenced
2012 – England launched (and finished in 2018) 100K genome project
2013 – Saudi Arabia launched the Saudi Human Genome Program
2015 – US launched plan to sequence one million genomes
2015 – Korea launched plan to sequence 10K genomes
2016 – US launched All of Us Research cohort to enroll one million or more participants to collect lifestyle, environment, genetic, and biologic data
2016 – China launched the Precision Medicine initiative with 60 billion RMB
2016 – France started Genomic Medicine 2025 Project
Treatments available today due to DNA technology
Knowing the structure and function of DNA has also enabled us to develop breakthrough biotechnology solutions that have greatly improved the quality of life of countless individuals. A few examples include:
Genetic screenings for diseases. An individual can scan his or her DNA code to look for known mutations linked to disease. Newborns are often screened at birth to identify treatable genetic disorders. For instance, all newborns in the US are screened for a disease called severe combined immunodeficiency (SCID). Individuals with this genetic disease lack a fully functional immune system and usually die within a year, if not treated. However, due to regular screenings, these newborns can receive a bone marrow transplant, which has a more than 90% of success rate to treat SCID. A well-known example in adults is screening women for mutations in the BRCA1 and BRCA2 genes as risk factor for developing breast cancer or ovarian cancer.
Recombinant protein production. This technology allows scientists to introduce human genes into microorganisms to produce human proteins that can be introduced back to patients to carry out vital functions. In 1978, the company Genentech developed a process to recombinantly produce human insulin, a protein needed to regulate blood glucose. Recombinant insulin is still used to treat diabetes.
CAR T cells. CAR T cell therapy is a technique to help your immune system recognize and kill cancer cells. Immune cells, called T-cells, from a cancer patient are isolated and genetically engineered to express receptors that allow them to identify cancer cells. When these modified T cells are put back into the patient they can help find and kill the cancer cells. Kymriah, used to treat a type of leukemia, and Yescarta, used to treat a type of lymphoma are examples of FDA approved CAR T cell treatments.
Gene therapy. The goal of gene therapy is to replace a missing or defective gene with a normal one to correct the disorder. The first in vivo gene therapy drug, Luxterna, was approved by the FDA in 2017 to treat an inherited degenerative eye disease called Leber’s congenital amaurosis.
Disclaimer: The authors above do not necessarily reflect the policies or positions of the organizations with which they are affiliated.
Frontiers in DNA technology
Our understanding of genetic data continues to lead to new and exciting technologies with the potential to revolutionize and improve our health outcomes. A few examples being developed are described below.
Organoids for drug screening. Organoids are miniature and simplified organs that can be developed outside the body with a defined genome. Organoid systems may one day be used to discover new drugs, tailor treatments to a particular person’s disease or even as treatments themselves.
CRISPR-Cas9. This is a form of gene therapy – also known as genetic engineering – where the genome is cut at a desired location and existing genes can either be turned off or modified. Animal models have shown that this technique has great promise in the treatment of many hereditary diseases such as sickle cell disease, haemophilia, Huntington’s disease, and more.
We believe sequencing will become a mainstay in the future of human health.
While genomic data is incredibly insightful, it is important to realize, genomics rarely tells the complete story.
Except for rare cases, just because an individual has a particular genetic mutation does not mean they will develop a disease. Genomics provides information on “what could happen” to an individual. Additional datasets such the microbiome, metabolome, lifestyle data and others are needed to answer what will happen.
Disclaimer: The authors above do not necessarily reflect the policies or positions of the organizations with which they are affiliated.
The role of the microbiome
Elizabeth O’Day & Elizabeth Baca
The microbiome is sometimes referred to as the ‘essential organ’, the’forgotten organ’, our ‘second genome’ or even our ‘second brain’. It includes the catalog of approximately 10-100 trillion microbial cells (bacteria, archea, fungi, virus and eukaryotic microbes) and their genes that reside in each of us. Estimates suggest we have 150 times more microbial DNA from more than 10,000 different species of known bacteria than human DNA.
Microbes reside everywhere (mouth, stomach, intestinal tract, colon, skin, genitals, and possibly even the placenta). The function of the microbiome differs according to different locations in the body and with different ages, sexes, races and diets of the host. Bacteria in the gut digest foods, absorb nutrients, and produce beneficial products that would otherwise not be accessible. In the skin, microbes provide a physical barrier protecting against foreign pathogens through competitive exclusion, and production of antimicrobial substances. In addition, microbes help regulate and influence the immune system. When there is an imbalance in the microbiome, known as dysbiosis, disease can develop. Chronic diseases such as obesity, inflammatory bowel disease, diabetes mellitus, metabolic syndrome, atherosclerosis, alcoholic liver disease (ALD), nonalcoholic fatty liver disease (NAFLD), cirrhosis, hepatocellular carcinoma and other conditions are linked to improper microbiome functioning.
Milestones in our understanding of the microbiome
1680s – Dutch scientist Antonie van Leeuwenhoek compared his oral and fecal microbiota. He noted striking differences in microbes between these two habitats and also between samples from individuals in different states of health.
1885 – Theodor Escherich first describes and isolates Escherichia coli (E. coli) from the feces of newborns in Germany
1908 – Elie Metchnikoff, Russian zoologist, theorized health could be enhanced and senility delayed by bacteria found in yogurt
1959 – Germ-free animals (mice, rats, rabbits, guinea pigs, and chicks) reared in stainless steel in plastic housing to study the effects of health in microbe-free environments
1970 – Dr. Thomas D. Luckey estimates 100 billion colonies of microbes in one gram of human intestinal fluid or feces.
1995 – Craig Venter and a team of researchers sequence the genome of bacterium Haemophilus influenza, making it the first organism to have its genome completely sequenced.
1996 – The first human fecal sample is sequenced using 16S rRNA sequencing.
2001- Scientist Joshua Lederberg credited with coining term “microbiome”.
2005 – Researchers identify bacteria in amniotic fluid of babies born via C-section
2006- First metagenomic analysis of the human gut microbiome is conducted
2007- NIH sponsored Human Microbiome Project (HMP) launches a study to define how the microbial species affect humans and their relationships to health
2009- First microbiome study showing an association between gut microbiome in lean and obese adults
2011- German researchers identify 3 enterotypes in the human gut microbiome: Baceroids, Prevotella, and Ruminococcus
2011- Gosalbes performed the first metatransciptomic analysis of healthy human gut microbiota
2012 – HMP unveils first “map” of microbes inhabiting healthy humans. Results generated from 80 collaborating scientific institutions found more than 10,000 microbial species occupy the human ecosystem, comprising trillions of cells and making up 1-3% of the body’s mass.
2012 – American Gut Project founded, providing an open-to-the-public platform for citizen scientists seeking to analyze their microbiome and compare it to the microbiomes of others.
2014 – The Integrative Human Microbiome Project (iHMP), begins with goal of studying 3 microbiome-associated conditions.
2016 – The Flemish Gut Flora Project, one of the world’s largest population-wide studies on variations in gut microbiota publishes analysis on more than 1,100 human stool samples.
2018 – The American Gut Project publishes the largest study to date on the microbiome. The results include microbial sequence data from 15,096 samples provided by11,336 participants across the US, UK, Australia and 42 other countries.
What solutions are already (or could be) derived from this dataset?
Biotechnology solutions based off microbiome data have already been developed or are in the process of development. A few key examples are highlighted below:
Probiotics. Probiotics are beneficial bacteria that may prevent or treat certain disease. They were first theorized in 1908 and are now a common food additive. From yogurts to supplements, various probiotics are available for purchase in grocery stores and pharmacies, claiming various benefits. For example probiotic VSL#3 has been shown to reduce liver disease severity and hospitalization in patients with cirrhosis.
Diagnostics. Changes in composition of particular microbes are noted as potential biomarkers. An example includes the ratio of Bifidobacterium to Enterobacteriaceae know as the B/E ratio. A B/E greater than 1 suggests a healthy microbiome and a B/E less than 1 could suggest cirrhosis or particular types of infection.
Fecal Microbiome transplantation (FMT). Although not FDA-approved, fecal microbiome transplantation (FMT) is a widely used method where a fecal preparation from a healthy stool donor is transplanted into the colon of patient via colonoscopy, naso-enteric tube, or capsules. FMT has been used to treat Clostridium difficile infections with 80-90% cure rates (far better efficacy than antibiotics).
Therapeutics. The microbiome dataset is also producing several innovative therapies. Development of bacteria consortia and single strains (both natural and engineered) are in clinical development. Efforts are also underway to identify and isolate microbiome metabolites with important function, such as the methicillin-resistant antibiotics that were identified by primary sequencing of the human gut microbiome.
By continuing to build the microbiome dataset and expand our knowledge of host-microbiome interactions, we may be able correct various states of disease and improve human health.
Disclaimer: The authors above do not necessarily reflect the policies or positions of the organizations with which they are affiliated.
The role of clinical data, and the doctor’s ‘sixth sense’
Pam Randhawa, CEO and founder of Empiriko Corporation, Andrew Steinberg, Watson Institute for International and Public Affairs, Brown University, Elizabeth Baca & Elizabeth O’Day
For centuries, physicians were limited by the data they were able to obtain via external examination of an individual patient or an autopsy.
More recently, technological advancements have enabled clinicians to identify and monitor internal processes which were previously hidden within living patients.
One of the earliest examples of applied technology occurred in the 1890s when German physicist Wilhelm Röntgen discovered the potential medical applications of X-rays.
Since that time, new technologies have expanded clinical knowledge in imaging, genomics, biomarkers, response to medications, and the microbiome. Collectively, this extended database of high quality, granular information has enhanced the physician’s diagnostic capabilities and has translated into improved clinical outcomes.

Today’s clinicians increasingly rely on medical imaging and other technology- based diagnostic tools to non-invasively look below the surface to monitor treatment efficacy and screen for pathologic processes, often before clinical symptoms appear.
In addition, the clinician’s senses can be extended by electronic data capture systems, IVRS, wearable devices, remote monitoring systems, sensors and iPhone applications. Despite access to this new technology, physicians continue to obtain a patient’s history in real-time followed by a hands-on assessment of physical findings, an approach which can be limited by communication barriers, time, and the physician’s ability to gather or collate data.
One of the largest examples of clinical data collection, integration and analysis occurred in the 1940s with the National Heart Act which created the National Heart Institute and the Framingham Heart Study. The Framingham Original Cohort was started in 1948 with 5,209 men and women between the ages of 30-62 with no history of heart attack or stroke.
Over the next 71 years, the study evolved to gather clinical data for cardiovascular and other medical conditions over several generations. Prior to that time the concepts of preventive medicine and risk factors (a term coined by the Framingham study) were not part of the medical lexicon. The Framingham study enabled physicians to harness observations gathered from individuals’ physical examination findings, biomarkers, imaging and other physiologic data on a scale which was unparalleled.
The adoption of electronic medical records helped improve data access, but in their earliest iterations only partially addressed the challenges of data compartmentalization and interoperability (silos).
Recent advances in AI applications, EMR data structure and interoperability have enabled clinicians and researchers to improve their clinical decision making. However, accessibility, cost and delays in implementing global interoperability standards have limited data accessibility from disparate systems and have delayed introduction of EMRs in some segments of the medical community.
To this day, limited interoperability, the learning curve and costs associated with implementation are cited as major contributors to physician frustration, burnout and providers retiring early from patient care settings.
However, an interoperability platform known as Fast Healthcare Interoperability Resources (FHIR, pronounced “FIRE”) is being developed to exchange electronic health records and unlock silos. The objective of FHIR is to facilitate interoperability between legacy health care systems. The platform facilitates easier access to health data on a variety of devices (e.g., computers, tablets, cell phones), and allows developers to provide medical applications which can be easily integrated into existing systems.
As the capacity to gather information becomes more meaningful, the collection, integration, analysis and format of clinical data submission requires standardization. In the late 1990s, the Clinical Data Interchange Standards Consortium (CDISC) was formed “to develop and support global, platform-independent data standards which enable information system interoperability to improve medical research”. Over the past several years, CDISC has developed several models to support the organization of clinical trial data.
Milestones in the discovery/development of clinical data and technologies
500BC – The world’s first clinical trial recorded in the “Book of Daniel” in The Bible
1747 – Lind’s Scurvy trial which contained most characteristics of a controlled trial
1928 – American College of Surgeons sought to improve record standards in clinical settings
1943 – First double blinded controlled trial of patulin for common cold (UK Medical Research Council)
1946 – First randomized controlled trial of streptomycin in pulmonary tuberculosis conducted (UK Medical Research Council)
1946 – American physicists Edward Purcell and Felix Bloch independently discover nuclear magnetic resonance (NMR).
1947 – First International guidance on the ethics of medical research involving human subjects – Nuremberg Code
1955 – Scottish physician Ian Donald begins to investigate the use of gynecologic ultrasound.
1960 – First use of endoscopy to examine a patient’s stomach.
1964 – World Medical Association guidelines on use of human subjects in medical research (Helsinki Declaration)
1967 – 1971 – English electrical engineer Godfrey Hounsfield conceives the idea for computed tomography. First CT scanner installed in Atkinson Morley Hospital, Wimbledon, England. First patient brain scan performed – October 1971.
1972 – First Electronic Health Record designed
1973 – American chemist Paul Lauterbur produces the first magnetic resonance image (MRI) using nuclear magnetic resonance data and computer calculations of tomography.
1974 – American Michael Phelps develops the first positron emission tomography (PET) camera and the first whole-body system for human and animal studies.
1977 – First MRI body scan is performed on a human using an MRI machine developed by American doctors Raymond Damadian, Larry Minkoff and Michael Goldsmith.
1990 – Ultrasound becomes a routine procedure to check fetal development and diagnose abnormalities.
Early-Mid 1990 – Development of electronic data capture (EDC) system for clinical trials (electronic case report forms)
1996 – International Conference on Harmonization published Good Clinical Practice which has become the universal standard for ethical conduct of clinical trials.
Late 1990s – The Clinical Data Interchange Standards Consortium (CDISC) was formed with the mission “to develop and support global, platform-independent data standards that enable information system interoperability to improve medical research”
2009 – American Recovery and Reinvestment Act of 2009 passed including $19.2 Billion of funding for hospitals and physicians to adopt EHRs
2014 – HL-7 International published FHIR as a “Draft Standard for Trial Use” (DSTU)
Emerging Solutions
The convergence of scientific knowledge, robust clinical data, and engineering in the digital age has resulted in the development of dynamic healthcare technologies which allow for earlier and more accurate disease detection and therapeutic efficacy in individuals and populations.
The emergence of miniaturized technologies such as handheld ultrasound, sleep tracking, cardiac monitoring and lab-on-a-chip technologies will likely accelerate this trend. Among the most rapidly evolving fields in data collection, has been in clinical laboratory medicine where continuous point-of-care testing, portable mass spectrometers, flow analysis, PCR, and use of MALDI-TOF mass spectrometry for pathogen identification provide insight into numerous clinically relevant biomarkers.
Coupled with high resolution and functional medical imaging the tracking of these biomarkers gives a metabolic fingerprint of disease, thereby opening a new frontier in “Precision Medicine”.
Beyond these capabilities, artificial intelligence (AI) applications are being developed to leverage the sensory and analytic capabilities of humans via medical image reconstruction and noise reduction. AI solutions for computer-aided detection and radiogenomics enable clinicians to better predict risk and patient outcomes.
These technologies stratify patients into cohorts for more precise diagnosis and treatment. As AI technology evolves, the emergence of the “virtual radiologist” could become a reality. Since the humans cannot gather, collate and quickly analyze this volume of granular information, these innovations will replace time-intensive data gathering with more cost-effective analytic approaches to clinical decision-making.
As the population ages and lives longer, increasing numbers of people will be impacted by multiple chronic conditions which will be treated contemporaneously with multiple medications. Optimally these conditions will be monitored at home or in another remote setting outside of a hospital.
Platforms are under development where the next generation of laboratory technologies will be integrated into an interoperable system which includes miniaturized instruments and biosensors. This will be coupled with AI driven clinical translation models to assess disease progression and drug effectiveness.
This digital data will be communicated in real time to the patient’s electronic medical record. This type of system will shift clinical medicine from reactive to proactive care and provide more precise clinical decision-making.
With this enhanced ability to receive more granular, high quality clinical information comes an opportunity and a challenge. In the future, the ability to leverage the power of computational modeling, artificial intelligence will facilitate a logarithmic explosion of clinically relevant correlations.
This will enable discovery of new therapies and novel markers which will empower clinicians to more precisely manage risk for individuals and populations. This form of precision medicine and predictive modeling will likely occur across the disease timeline, potentially even before birth.
Stakeholders will need to pay close attention to maintaining the privacy and security of patient data as it moves across different platforms and devices.
However, the potential benefits of this interoperability far outweigh the risks. This will raise a host of ethical questions, but also the potential for a series of efficiencies which will make healthcare more accessible and affordable to a greater number of people.
Disclaimer: The authors above do not necessarily reflect the policies or positions of the organizations with which they are affiliated.
Lifestyle and environmental data
Jessica Shen, Vice President at Royal Philips, Elizabeth Baca & Elizabeth O’Day
In medicine and public health there is often tension between the effect of genetics verses the effect of the environment, and which plays a bigger role in health outcomes. But rather than an either or approach, science supports that both factors are at play and contribute to health and disease.
For instance, one can be genetically at risk for diabetes, but with excellent diet and exercise and a healthy lifestyle, the disease can still be avoided.
In fact, many people who are newly diabetic or pre-diabetic can reverse the course of their disease through lifestyle modifications. Alternatively, someone at risk of asthma who is exposed to bad air quality can go on to develop the disease, but then become relatively asymptomatic in an environment with less triggers.
The growing literature on the importance of lifestyle, behaviours, stressors, social, economic, and environmental factors, (the latter also known as the social determinants of health), have been relatively hard to capture for real time clinical information.
It has been especially challenging to integrate all of the data together for better insight. However, that is changing. In this new data frontier, the growth of data in the lifestyle and environment area offer huge potential to bridge gaps, increase understanding of health in daily life, and tailor treatments for a precision health approach.
Milestones
1881 – Blood pressure cuff invented
2010 – Asthmapolis founded with sensor to track environmental data on Asthma/COPD rescue inhalers
2011 – First digital FDA blood pressure cuff approved and links to digital phone
2012 – AliveCor receives FDA approval for EKG monitor with Iphone
2017 – 325,000 mobile health apps
2017 – FDA releases Digital Health Innovation Action Plan
2018 – FDA approves first continuous glucose monitor via implantable sensor and mobile app interface
What are some of the benefits suggested with the use of lifestyle data?
Mobile technology has enabled more continuous monitoring in daily life outside of the clinic and in real world settings. As an example the traditional blood pressure cuff invented over 130 years ago was only updated in the last decade to allow remote readings which are digitally captured.
Sensors are now being included to measure environmental factors such as air quality, humidity, and temperature. Other innovations are allowing mood to be captured in real time, brain waves for biofeedback, and other biometrics to improve fitness, nutrition, sleep, and even fertility.
The personal analytics capabilities of devices designed to collect lifestyle data can contribute to health by aiding preventive care and help with the management of ongoing health problems.
Identification of health problems through routine monitoring may evolve into a broad system encompassing many physiologic functions; such as:
- sleep disturbances (severe snoring; apnea)
- neuromuscular conditions (identification of early Parkinson’s with the analysis of muscular motion)
- cardiac problems such as arrhythmias including atrial fibrillation
- sensors to detect early Alzheimer’s disease via voice changes
The Apple Watch has provided documentation on the use of the device for arrhythmia detection, the series 4 version can generate a ECG similar to a Lead 1 electrocardiogram; claims related to these functions were cleared by FDA (Class II, de Novo). Additional wearable technologies are likely to incorporate such functions in the future.
The instant feedback available with the use of a wearable sensory device can serve as an aid to the management of many chronic conditions including but not limited to diabetes, pulmonary problems, and hypertension.
Many studies have documented the cardiovascular benefits of life-long physical activity. Several biotechnology solutions, designed to track activity with analytical feedback tools provide the opportunity to encourage physical activity to promote health, perhaps even modifying behaviour. A Cochrane Review (Bravata, 2007. PMID 18029834) concluded there was short-term evidence of significant physical activity increase and associated health improvement with the use of a pedometer to increase activity. The feedback associated with today’s data driven health improvement applications should increase the effectiveness over a simple mechanical pedometer. Studies are underway in multiple settings to support the use of activity trackers and feedback-providing analysis tools as beneficial to longer-term health.
Use in research settings
In many circumstances, the collection of clinical data for a formal trial or for use in longitudinal studies is facilitated by direct observation as provided by a network-attached sensor system.
What may future developments support?
The development of ‘smart clothing’ and wearable tech-enabled jewellery as well as implantable devices will lead to less obtrusive observation instruments recording many more physiological indicators.
Wireless networking, both fixed and mobile, continue their stepwise jumps in speed and this capacity growth (5G and Wifi-6 with megabit internet) will support massive increases in the volume of manageable data.
Connecting sensor derived observations to other indicators of health such as medical history and genetics will further expand our understanding of disease and how to live our most healthy lives.
However, for this potential to be realized significant technical and ethical issues must first be addressed.
Disclaimer: The authors above do not necessarily reflect the policies or positions of the organizations with which they are affiliated.
How to put patients at the centre of innovation
Elissa Prichep, Precision Medicine Lead at the World Economic Forum, Elizabeth Baca & Elizabeth O’Day
The Global Future Council on biotechnology has examined the exponential growth of data across different areas which has lead to breakthrough technologies transforming human health and medicine. Yet let us be clear: it was not some abstract understanding of data that lead to these solutions, it was real data, derived from real individuals, individuals like you. Your data, or data from someone like you, led to those solutions. Did you know that? Did you consent to that?
We believe individuals should feel empowered by contributing to these datasets. You are changing human health- there’s perhaps nothing more important. However, in going through this analysis we were repeatedly concerned about the whether the individuals (“data-contributors”) were properly informed or consented by “data collectors” to use their data?
As we have documented here, amazing, breakthrough technologies and medicines can arise from these datasets. However, there are nefarious situations that could develop as well.
We believe new norms between “data-collectors” and “data contributors”need to be established if we want data to continue to drive the development of biotech solutions to improve human health.
How we think about privacy will change
Although the emergence of digital data through electronic health records, mobile applications, cloud storage and more have had great benefits, there are also privacy risks.
The identification of parties associated with ‘anonymous’ data becomes more likely as more sophisticated algorithms are developed; data that is secure and private today may not be so in the future. Data privacy concerns and data theft along with device hacking are a serious concern today and will only become more so as the volume and types of data collected increase.
As more data is combined, there is a greater risk of reidentification or privacy breaches. For example, when a Harvard professor was able to reidentify more than 40% of the participants in the anonymous genetic study, The Personal Genome Project.
Additionally, as other types of data are added in for health purposes, in retail for example, there is the risk that reidentification can expose private health details, for example when Target identified the pregnancy of a teenage girl to her family.
There must be value from these solutions to entertain the risks associated with combining the data. Integrating patient and participants at the centre of design ensures informed consent and a better likelihood of value that balances the risks and trade-offs.
Inclusion of diverse populations is important for the new insights to have a positive impact
The benefits and risks a patient can expect from an intervention can depend heavily on that person’s unique biological make-up. A 2015 study found that roughly 20% of new drugs approved in the previous six years demonstrated different responses across different racial and ethnic groups.
However, therapeutics are often put on the market without an understanding of the variability in efficacy and safety across patients because that is not assessed in clinical trials, either due to lack of diversity in the trial, lack of asking the right questions, or both. In the US, it is estimated that 80-90% of clinical trial participants are white despite FDA efforts to expand recruitment.
Without an intentional effort, the amassed new knowledge through biotech solutions, if not done with a diverse population, will not yield accurate insight. If the biotech solutions are not representative of the population, there is the potential to increase health disparities.
For example, genetic studies incorrectly inferred an increased risk of hypertrophic cardiomyopathy for African Americans since the genetic insights were largely gathered from anglo populations.
There are many reasons that participation has been so low in research, but authentic engagement, understanding the historical context, and intentionally funding research to increase participation and improve diversity in translational efforts are already on their way such as the All of Us Cohort and the California Initiative to Advance Precision Medicine.
Inclusive participation will help understand where people truly are in their health journey
In the clinical setting, patient centeredness also needs to occur. Healthy individuals are amassing more and more data about themselves and patients with chronic disease are also starting to rely on applications to track everything from sleep to environmental exposures to mood, but this is currently not used to increase insight for health and illness.
As patients and healthy people take charge of their data, it can only be used if they agree to share it. As biotech solutions are developed, integrating data across all the various areas will be vital to truly have an impact.
Next Steps in Biotech Health Solutions
At the start of this series, we asked: what if your doctor could predict your heart attack before you had it? Research is underway to do just that through combining data from the proteome, patient reported symptoms, and biosensors.
Big data analysis is also already yielding new leads to paediatric cancer when looking at the genetic information of tumors. In the future, this is likely to move beyond better treatment to better prevention and earlier detection. And in the case where treatment is needed, a more tailored option could be offered.
The impact of this data on improved health is exciting and impacts each of us. As data grows, increased understanding does as well. Each of us has the opportunity to be a partner in the new data frontier.
Disclaimer: The authors above do not necessarily reflect the policies or positions of the organizations with which they are affiliated.
References:












{kind=link}